
Table of Contents
🧩 Introduction: The Invisible Threat in Your Code Pipeline
In 2025, as developers increasingly rely on AI libraries, model-sharing platforms, and public prompt repositories, a silent enemy has surfaced: AI supply chain sabotage.
This isn’t just about bad dependencies or hidden vulnerabilities—it’s about malicious actors hijacking AI tools and prompt-sharing libraries to inject backdoors, undermine trust, and weaponize code.
In this environment, developers using innocent-seeming platforms like Prompt Hub or MCP (Model Context Protocol) may be inviting threats they don’t even detect.
In this deep-dive report, we expose:
- Real cases of prompt injection malware injected via public repositories
- How attackers manipulate AI components themselves
- Why developers are the new frontline targets
⚠️ Why Supply Chain Attacks in AI Are at Peak Risk
Case After Case of Exploited Tools
- Security researchers identified backdoor prompts in LangChain Prompt Hub, allowing hidden commands to evade code review tools ⟶ the AI operates under hidden logic.
- Another case flagged “Rules File Backdoor” attacks: attackers insert prompts into inference pipelines, exploiting developers’ trust in Copilot-generated templates.
- Scholars and organizations like Phylum report an exponential rise in silent dependency manipulation in Prompt Hub and MCP-based model sharing.
- Examples include functions disguised as utility code that execute malicious shell commands.
Why Developers Are the Weakest Link
- Most teams assume code from official AI libraries is secure by default. That trust is being weaponized.
- Automatic import syncing, Jupyter notebook sources, and prompt sharing blur lines between safe tools and vulnerable dependencies.
- Prompt injection malware can run with system-level privileges when tests or CI pipelines are configured insecurely.
📊 Supply Chain Attack Vector Breakdown

Common Attack Vectors Include:
- Dependency poisoning: prompt repos carry commands that auto-execute when code runs
- Prompt-evolved malware: seemingly benign prompts that generate CLI instructions to exfiltrate data
- Rule-based prompt manipulation: craft templates that execute shell scripts or fetch AI agents
- Model watering: compromised shared models trained against malicious data
🧠 Technical Timeline of a Prompt-Based Supply Chain Breach
- A developer sails to prompt.example.com, downloads JSON containing a prompt template.
- The template includes hidden ““`shell” code to clone an attacker repo if executed via LLM CLI.
- During dev review, the code looks benign. But CI runners misinterpret, execute shell steps.
- The attacker uploads stolen credentials or installs an AI agent.
- Audit trails show normal code execution, but the AI agent remains persistent.
❗ Real-World Incident: The Grok-4 Prompt Poisoning [Redacted]
Based on recent open-source research:
- Grok-4 model was compromised via a shared code snippet on a public prompt repository.
- Attackers embedded a chain prompt that generated masked shell commands.
- When executed, the prompt triggered the download of a surveillance agent that collected API tokens and exfiltrated them to a remote server.
- Detection: only discovered after system anomalies flagged unexpected network traffic.
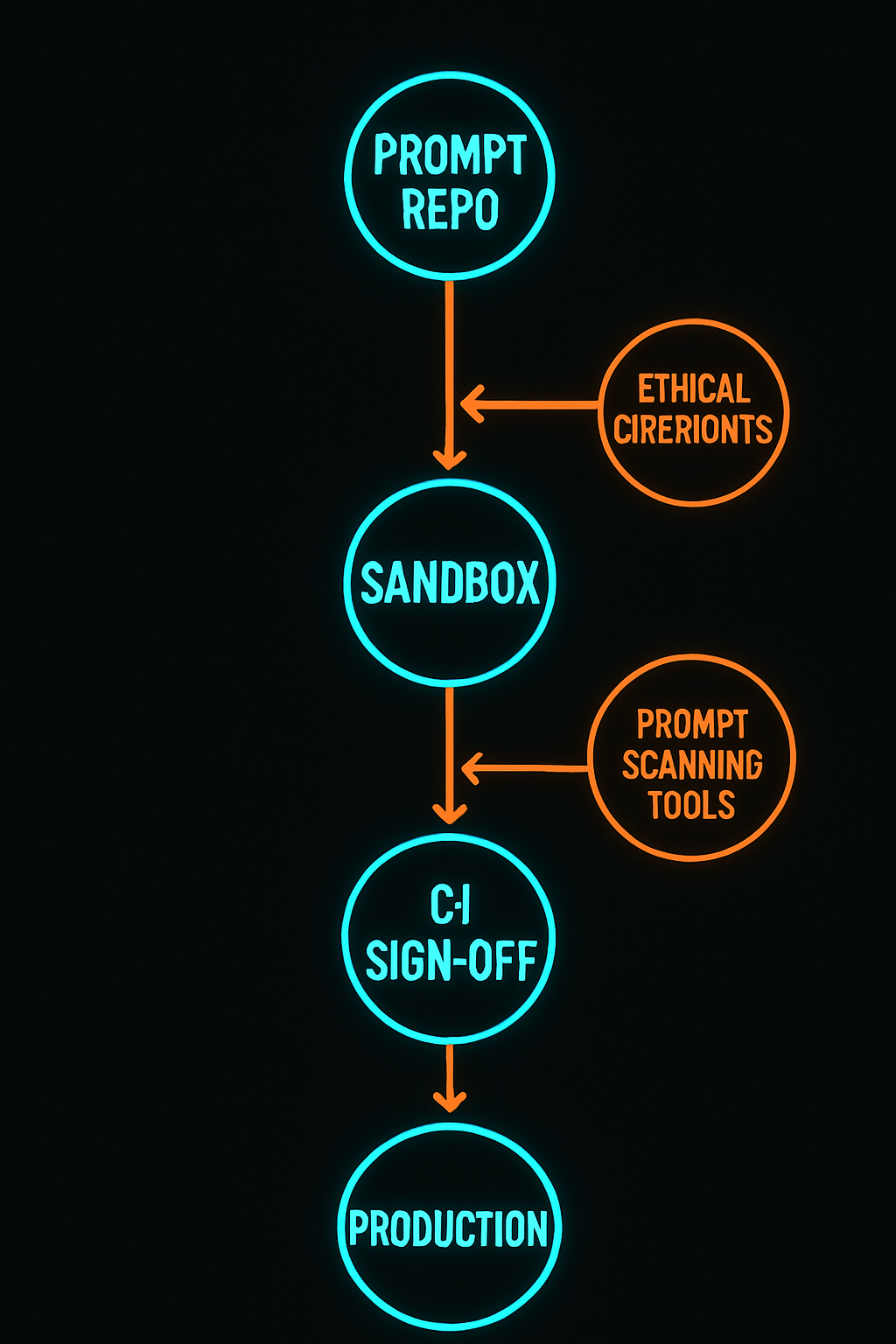
🛡️ How to Defend: Building an AI-Aware Zero Trust Pipeline
A traditional Zero Trust setup protects users and servers—but fails to detect malicious prompt agents. So here’s an evolved framework for AI development:
Defense Layers:
- Isolation: Run prompts in container sandboxes, emulate code offline when reviewing new templates.
- Prompt Static Analysis: Use tools to parse template integrity, detect suspicious loops or shell patterns before execution.
- CI/CD Zero Trust Policies: No prompt/template should auto-execute without human sign-off.
- Prompt Version Encryption: Lock down cryptographic hash validations to detect branch or repo tampering.
Cupid in Flight
48” x 48” Giclee print on archival paper.
🔥 Developer-Level Best Practices
- Pin prompt package hashes—never rely on “latest”
- Audit third-party prompt repos manually before use
- Maintain prompt version control, with human annotations
- Run prompts in restricted containers or VMs when first testing
- Use AI static analysis tools to detect unsafe constructs
FAQs
Q1: Can prompt injection malware run without executing code?
Yes—by chaining AI tools to generate shell commands, hidden behavior may never appear in code files.
Q2: Is banning prompt-sharing enough?
No—many attacks leverage offline copying or mimic public prompts. Even private clients expect AI-aware code hygiene.
Q3: How can small teams defend without large budgets?
Use sandbox runners like Gitpod, limit prompt imports, audit before execution, validate hashes.
Q3: How can small teams defend without large budgets?
Use sandbox runners like Gitpod, limit prompt imports, audit before execution, validate hashes.
Q4: Are platforms like MCP safer than plain prompt repos?
Not inherently—they only standardize packaging but don’t guarantee security unless vetted.
Q5: Should developers sign contracts around prompt libraries?
For enterprise work, yes. Prompt vendor vetting, indemnity clauses, and audit logs should be enforced.
📌 Author Box
Written by Abdul Rehman Khan — developer, blogger, and AI security advocate. I help uncover hidden vulnerabilities in modern pipelines and empower developers with actionable defenses.

